Blacklists and whitelists - Do not check / Only follow / Do not follow
In a nutshell, 'check' means ask the server for the status of that page without actually visiting the page. 'Follow' means visit that page and scrape the links off it.
Checking a link is sending a request and receiving a status code (200, 404, whatever). Integrity and Scrutiny will check all of the links it finds on your starting page. If you've checked 'Check this page only' then it stops there.
But otherwise, it'll take each of those links it's found on your first page and 'follow' them. That means it'll request and load the content of the page, then trawl the content to find the links on that page. It adds all of the links it finds to its list and then goes through those checking them, and if appropriate, following them in turn.
Note that it won't 'follow' external links, because it would then be crawling someone else's site - it just needs to 'check' external links
You can ask Integrity or Scrutiny to not check certain links, to only follow or not to follow certain links. You do this by setting up a rule and typing part of a url into the relevant box. For example, if you want to only check the section of your site below /engineering you would choose 'Only follow...' and type '/engineering' (without quotes). You don't need to know about pattern matching such as regex or wildcards, just type a part of the url. Separate multiple keywords or phrases with commas.
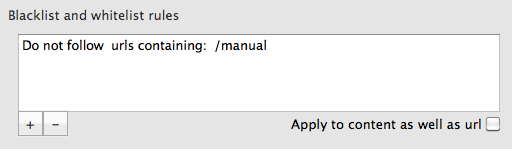
You can now limit the crawl based on keywords or a phrase in the content, or highlight certain pages based on content.
No complex pattern-matching, just type the word or phrase and check 'Check content as well as url'. A match is made if any of the phrases appear in the url or the content.
You can highlight pages that are matched by the 'do not follow' or 'only follow' rules. This option is on the first tab of Preferences. This can be used, for example, to find 'soft 404s' where some systems return a default page and a 200 status code when a file isn't found. Type a phrase into 'do not follow' that appears on the soft 404 page and set highlighting of blacklisted pages.
Number of threads
This slider sets the number of requests that Scrutiny/Integrity can make at once Using more threads may crawl your site faster, but it will use more of your computer's resources and your internet bandwidth, and also hit your website harder.
Using fewer will allow you to use your computer while the crawl is going on with the minimum disruption.
The default is 12, minimum is one and maximum is 40. I've found that using more than this has little effect. If your site is fast to respond, then you may get maximum crawl speed with the slide half way.
Beware - your site may start to give timeouts if you have this setting too high. In some cases, too many threads may stop the server from responding or responding to your IP. If moving the number of threads to the minimum doesn't cure this problem, see 'Timeout and Delay' below.
Timeout and Delay
If you're getting timeouts you may first reduce the number of threads you're using.
Your server may not respond to many simultaneous requests - it may have trouble coping or may deliberately stop responding if being bombarded from the same IP. If you get many timeouts at the same time, there are a couple of things you can do. First of all, move the number of threads to the extreme left, then Scrutiny/Integrity will send one request at a time, and process the result before sending the next. This alone may work. If not, then the delay field allows you to set a delay (in seconds). You can set this to what you like, but a fraction of a second may be enough.
If your server is simply being slow to respond or your connection is busy, you can increase the timeout (in seconds).
Archive pages while crawling
When Integrity crawls the site, it has to pull in the html code for each page in order to find the links. WIth the archive mode switched on, it simply saves that html as a file in a location that you specify at the end of the crawl.
If you need to go back and refer to them or use them as a backup that's fine but it doesn't alter those files in any way (eg making the links relative) so they're not particularly user-friendly if you want to view them.
Ignore querystrings
The querystring is information within the url of a page. It follows a '?' - for example www.mysite.co.uk/index.html?thisis=thequerystring. If you don't use querystrings on your site, then it won't matter whether you set this option. If your page is the same with or without the querysrting (for example, if it contains a session id) then check 'ignore querystrings'. If the querystring determines which page appears (for example, if it contains the page id) then you shouldn't ignore querystrings, because Integrity or Scrutiny won't crawl your site properly.
Don't follow 'nofollow'
Scrutiny 4.1 can check links for the 'rel = nofollow' attribute. The check is off by default - you can switch it on if you need it. If you wish to follow all links but see which links have nofollow, you can do so. Or you can ask Scrutiny not to follow those 'nofollow' links.
To check for nofollow in links, go to Preferences > Views and switch on nofollow in one or both of the links tables. With the column showing in either view, Integrity / Scrutiny will check for the attribute in the links it finds, and show Yes or No in the table column. (You can of course re-order the table columns by dragging and dropping).
You'll find the checkbox for 'don't follow 'nofollow' links' on the Sites and Settings screen. With that unchecked, Scrutiny will still follow those links.
Scrutiny can also check for nofollow in the robots meta tag. If it finds it then it'll treat and mark all links on that page as being nofollow and won't follow those if the 'don't follow' checkbox is checked.
Pages have unique titles
Choosing this option is a quicker and more accurate way to crawl your site, but it only works if each of your pages has a different title.
After checking each internal link, the app has to then fetch the contents of the page, read through it and pull out the links from that page. That's how it crawls the site. It'll get a link like "index.html" lots of times (on every page perhaps) so before fetching the contents, it has to decide whether it's done that page already. It compares the new link with the list of those it's already done.
By default, Integrity and Scrutiny use the url to determine this. However, it's often the case that the same page is referred to by a number of different urls - eg peacockmedia.co.uk and peacockmedia.co.uk/index.html are the same page, but a web crawler can't know that. Some content management systems can refer to the same page by quite a few different urls. That means that the app could do lots more work than it needed to, and over-report the number of links and pages.